qql-go and QQL Retrieval Operations for Qdrant
Learn how qql-go turns QQL into a single-binary CLI for Qdrant retrieval operations, CI checks, runbooks, and agent-safe automation.
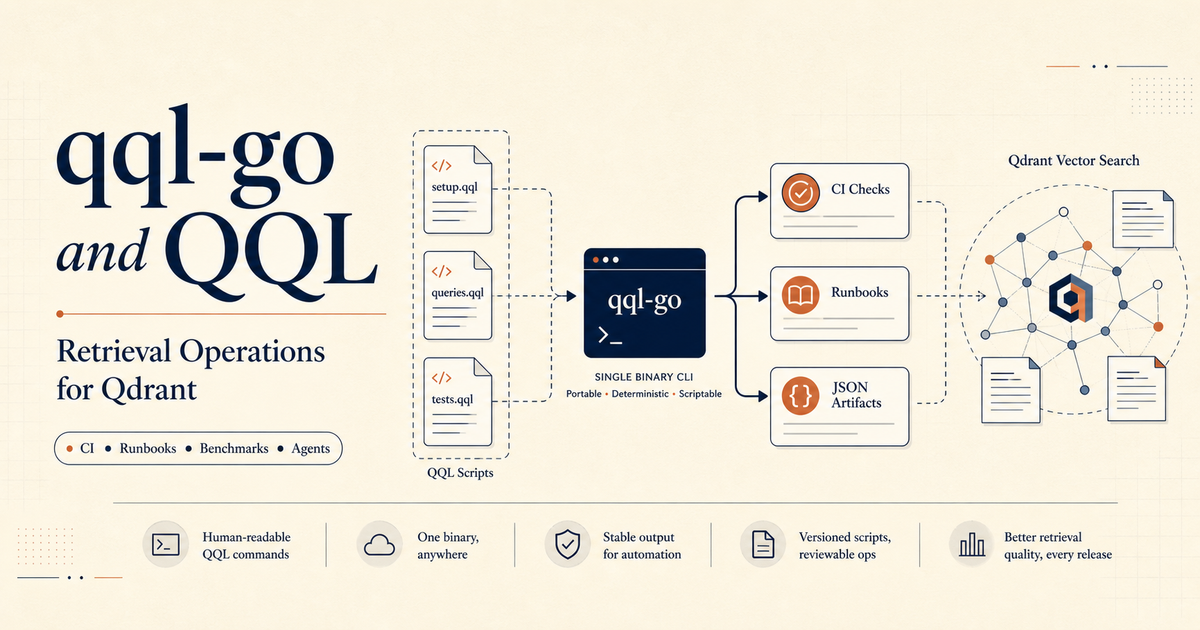
Introduction#
The first thing people notice about QQL is the syntax, but the deeper story is retrieval operations: readable statements instead of hand-written payloads, a query language that feels closer to SQL than to a vector-database SDK.
You can express semantic search, hybrid dense-sparse retrieval, filters, collection setup, indexes, and Qdrant operations as short commands that a human can scan quickly.
That readability matters. But while working on qql-go, the more interesting angle became clearer:
QQL can also be an operational interface for retrieval systems.
Not necessarily the thing you put on the hot path of your application. The thing you use around the app: CI checks, regression suites, debug runbooks, benchmark packs, cron jobs, shell scripts, and agent workflows that need deterministic access to Qdrant.
This post is about that retrieval operations angle: where qql-go comes from, why it exists next to the original Python QQL, and which workflows it is actually good at.
QQL Did Not Start With qql-go#
QQL did not start in Go.
The original project was created by Kameshwara Pavan Kumar Mantha as a SQL-like query language and CLI for Qdrant, built on top of the Python client.1 It takes human-readable statements such as SEARCH, INSERT, SCROLL, RECOMMEND, UPDATE, DELETE, and CREATE COLLECTION and maps them to Qdrant operations.
That Python implementation is not just a syntax sketch. It already supports serious retrieval workflows: hybrid dense-sparse search, grouped search, reranking, payload filters, quantization, script execution, and dump/restore.1
In other words, Python QQL is the readable query layer for Qdrant. It proves that a vector database can expose a familiar query language without turning into a heavy framework.
qql-go is an independent Go implementation inspired by that idea.2 I maintain the Go binary and also contribute on the Python side, so this is not a fork-versus-original story. It is one language idea explored through multiple runtimes and deployment models.
The useful split looks like this:
- Use Qdrant SDKs when you need maximum flexibility in application code and typed integration inside services.
- Use Python QQL when you want readable Qdrant workflows in the Python ecosystem: scripts, notebooks, and orchestration code.
- Use qql-go when you want a single binary with stable JSON output, versioned
.qqlscripts, and first-class support for CI, runbooks, benchmarks, and agent-safe automation.
The SDK builds the application. QQL makes retrieval work readable. qql-go makes that work portable.
Why Retrieval Needs Operations Tooling#
Modern RAG systems rarely fail with a clean exception. They fail quietly.
A chunking change moves the right document out of the top five. A new embedding model improves most queries but breaks a few high-value ones. A payload schema change makes a filter stop matching. A quantization tweak improves latency at the cost of recall. A reranker changes ordering just enough that answers get worse.
The application still returns 200 OK. The LLM still sounds confident. But the user sees "search got worse."
That is why retrieval evaluation guidance keeps separating retrieval quality from answer quality. You need to know whether the retriever surfaced the right evidence before you blame the model.34
In practice, teams ask the same boring but crucial questions:
- Did this query still return the expected document?
- Did hybrid search behave differently from dense-only or sparse-only search?
- Did tenant or department filters still apply after a schema change?
- Did latency or result count move beyond what the app can tolerate?
- Did vector index changes quietly degrade recall?
Most teams answer those questions with ad hoc notebooks, one-off scripts, or bits of application code pasted into a REPL. That works once. It does not scale to repeatable retrieval operations.
This is the gap qql-go is built around:
qql-go exec --quiet --json \
"SEARCH docs SIMILAR TO 'refund policy' LIMIT 3 USING HYBRID"That command is small enough to run in CI, readable enough to paste into an incident channel, and structured enough for automation or agents.
Workflow 1: Retrieval Regression CI#
The strongest qql-go story is retrieval regression testing.
Imagine this pull request lands:
- new embedding model
- new chunking logic
- different sparse retrieval configuration
- new reranker or scoring fusion
- payload schema changes
- index or quantization tuning
The app still boots. The REST endpoint still returns JSON. The LLM still produces fluent answers. But retrieval quality may have drifted in a way that only shows up under real workloads.
The release-validation example in the qql-go repository treats this as a CI problem instead of a vague monitoring problem.5 A small suite encodes the expectations:
{
"collection": "release_validation_docs",
"collection_expect": {
"topology": "hybrid",
"min_points": 6,
"payload_indexes": ["team", "title"]
},
"checks": [
{
"id": "04-hybrid-refund",
"command": "exec",
"statement": "SEARCH release_validation_docs SIMILAR TO 'refund policy for annual plan' LIMIT 3 USING HYBRID",
"expect": {
"min_results": 3,
"hybrid": true,
"top_ids": ["1101"]
}
}
]
}Then GitHub Actions installs the binary and runs the suite against an existing Qdrant collection:
name: retrieval-regression
on:
pull_request:
paths:
- "examples/release-validation/**"
- ".github/workflows/retrieval-regression.yml"
jobs:
retrieval-regression:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install qql-go
run: |
INSTALL_DIR="$RUNNER_TEMP/bin" curl -fsSL https://raw.githubusercontent.com/srimon12/qql-go/main/install.sh | sh
echo "$RUNNER_TEMP/bin" >> "$GITHUB_PATH"
- name: Run retrieval regression against existing Qdrant
env:
QDRANT_URL: ${{ secrets.QDRANT_URL }}
QDRANT_API_KEY: ${{ secrets.QDRANT_API_KEY }}
run: bash examples/release-validation/run-demo.shThe important artifact is not the YAML. It is the JSON evidence qql-go emits: result IDs, scores, payloads, explain plans, and validation failures.
If refund policy for annual plan stops returning document 1101 at rank 1, CI can fail the pull request with a diff you can actually review instead of a vague report that "search feels off."
That is retrieval operations as a release gate, not a dashboard you remember to check later.
Workflow 2: Retrieval Debug Runbooks#
The second workflow is production debugging.
A customer reports:
"Search stopped finding our billing policy docs."
This is where notebooks get awkward. The support engineer might not have the right Python environment. The on-call engineer might be SSH'd into a box. The incident channel needs a copy-pasteable runbook, not a pointer to someone's personal notebook.
The retrieval-debug-runbook example is built for that moment:5
# 1. Check connection health
qql-go doctor --quiet --json
# 2. Inspect collection shape
qql-go exec --quiet --json \
"SHOW COLLECTION retrieval_debug_runbook"
# 3. Explain hybrid query plan
qql-go explain --quiet --json \
"SEARCH retrieval_debug_runbook SIMILAR TO 'billing policy search regression after index removal' LIMIT 3 USING HYBRID"
# 4. Compare retrieval modes
qql-go exec --quiet --json \
"SEARCH retrieval_debug_runbook SIMILAR TO 'billing policy search regression after index removal' LIMIT 3 USING HYBRID"
qql-go exec --quiet --json \
"SEARCH retrieval_debug_runbook SIMILAR TO 'billing policy search regression after index removal' LIMIT 3 USING SPARSE"
qql-go exec --quiet --json \
"SEARCH retrieval_debug_runbook SIMILAR TO 'billing policy search regression after index removal' LIMIT 3 EXACT"
# 5. Rerun with a business filter
qql-go exec --quiet --json \
"SEARCH retrieval_debug_runbook SIMILAR TO 'billing policy search regression after index removal' LIMIT 3 USING HYBRID WHERE team = 'billing'"
# 6. Inspect expected document directly
qql-go exec --quiet --json \
"SELECT * FROM retrieval_debug_runbook WHERE id = 4104"This sequence does not try to be clever. It walks the stack: connection, collection schema, query plan, retrieval mode differences, filters, and expected payload.
That structure matters because Qdrant exposes dense vectors, sparse vectors, hybrid fusion, payload filters, grouping, reranking, and quantization controls.67 Production failures can come from any of those layers.
qql-go makes that JSON artifact part of the normal workflow.
Workflow 3: Agent-Safe Retrieval for Qdrant#
Agents add another twist.
An agent that needs to diagnose a failing query does not always need full SDK access:
client.delete_collection(...)
client.recreate_collection(...)
client.upsert(...)
client.search(...)That is too much surface area when the task is simply:
Find out why the expected policy document is not ranking.
A narrower, read-first command surface is easier to govern and easier to debug:
qql-go exec --quiet --json \
"SHOW COLLECTION docs"
qql-go explain --quiet --json \
"SEARCH docs SIMILAR TO 'HIPAA policy' LIMIT 5 USING HYBRID"
qql-go exec --quiet --json \
"SEARCH docs SIMILAR TO 'HIPAA policy' LIMIT 5 USING HYBRID WHERE department = 'compliance'"From an agent's perspective, this has the right properties:
- non-interactive execution
- compact JSON output
- explicit command strings
- read-first runbooks with a fixed order
- a surface that humans, CI, cron jobs, and agents can all share
This lines up with the broader movement toward deterministic tool boundaries, machine-readable CLIs, and auditable execution traces in agent systems.89
In that framing, qql-go is just a well-behaved tool: one binary, stable JSON, explicit commands.
Workflow 4: Benchmark Packs for Retrieval Quality#
The medical-retrieval-ops example explores another angle: reproducible retrieval benchmarks.5
It builds a corpus from ChatMED-Project/RAGCare-QA, loads it into Qdrant, and compares several modes:
- dense retrieval
- sparse retrieval
- hybrid RRF
- hybrid DBSF
- exact search
The benchmark reports hit@1 and hit@5 and ships as a folder of artifacts:
medical-retrieval-ops/
├── 01-provision.qql
├── build-medical-corpus.py
├── generated/
│ ├── 02-seed.qql
│ ├── benchmark-questions.json
│ └── eval.json
├── run-demo.sh
├── run-benchmark.sh
└── artifacts/The domain is medical, but the shape is general: benchmark packs instead of one-off notebooks.
Teams can clone, run, and diff these packs against their own clusters, using their own hybrid configurations and datasets. That matters because hybrid search in Qdrant is not one thing. It is a set of options: dense, sparse, multiple fusion strategies, reranking, filters, and search-time tuning.67
You should test those choices on your actual workload, not just on a generic sample.
qql-go does not replace a full RAG evaluation platform. It gives the retrieval layer a portable test harness that can feed one.
QQL Files Make Retrieval Work Reviewable#
Application code is not the only thing that belongs in git.
Retrieval operations should be versioned too:
- collection setup and payload indexes
- seed data for fixtures and smoke tests
- regression suites and runbooks
- benchmark queries and cron-job scripts
With qql-go, those can live as .qql files:
CREATE COLLECTION docs HYBRID
CREATE INDEX ON COLLECTION docs FOR department TYPE keyword
CREATE INDEX ON COLLECTION docs FOR doc_type TYPE keyword
SEARCH docs SIMILAR TO 'refund policy' LIMIT 3 USING HYBRID
SEARCH docs SIMILAR TO 'billing portal invoice download' LIMIT 3 USING SPARSE
SEARCH docs SIMILAR TO 'security compliance and audit logs' LIMIT 6 USING HYBRID GROUP BY department GROUP_SIZE 2Automation then runs them:
qql-go execute --stop-on-error smoke-tests.qqlThis is not Terraform for all of Qdrant. The better analogy is database migration files and operational scripts: small, explicit, reviewable files that encode what the retrieval system should look like and how it should behave.
Retrieval systems drift. Payload fields get renamed. Filters stop matching. Grouped searches subtly change tenant mix. CI should make that drift visible.
qql-go's retrieval operations job is to make that drift legible.
Where qql-go Fits#
The boundary for qql-go should stay crisp.
Use the Qdrant SDK when:
- retrieval runs on the application request path
- retrieval logic is part of product behavior
- you need typed integration in a service
- you are composing Qdrant calls with domain logic
Use Python QQL when:
- you are building readable Qdrant workflows in Python
- you want to mix QQL with notebooks, data pipelines, or orchestration code
- you prefer Python's ecosystem for data loading and analysis
Use qql-go when:
- CI needs retrieval smoke tests and regression checks
- support and on-call need copyable runbooks
- operators need quick collection inspection and explain plans
- benchmarks and demos should be reproducible
- agents need a constrained, read-first retrieval command surface
- scripts need stable JSON output and version-controlled
.qqlfiles
qql-go is not an ORM, a full SQL layer over Qdrant, a replacement for the SDKs, or a way to ignore the original Python QQL project.
It is a compact CLI for repeatable Qdrant operations, optimized for retrieval quality, debuggability, and automation.
The syntax makes Qdrant easier to read. The binary makes retrieval workflows easier to repeat.
A Practical Starting Workflow#
If you want to adopt qql-go without overbuilding, start small.
- Create a read-only regression suite.
- Pick five to ten business-critical queries, the kind that would embarrass you if they broke.
- Store the query statements and expected outcomes in git.
- Run
qql-goin CI against staging or a dedicated validation cluster. - Upload JSON artifacts for later inspection.
- Add a support runbook for the same failure cases.
- Feed production failures back into the offline suite.
The folder can be simple:
retrieval/
├── regression-suite.json
├── smoke-tests.qql
└── run-regression.shThe commands can be simple too:
qql-go doctor --quiet --json
qql-go exec --quiet --json "SHOW COLLECTION docs"
qql-go execute --stop-on-error smoke-tests.qqlThat habit, a small maintained retrieval regression suite and a few battle-tested runbooks, is exactly what qql-go is built to support.
Conclusion#
QQL is not one repository or one runtime.
It is a language idea: make Qdrant operations easier to read, write, and repeat.
The original Python QQL proves the readability angle. Qdrant SDKs remain the right foundation for application logic. qql-go explores what happens when the same idea becomes a portable operations layer: one Go binary, stable JSON, versioned scripts, CI checks, debug runbooks, benchmark packs, and a constrained command surface for AI agents.
AI coding tools have made SDK boilerplate cheaper, but they have not removed the need for commands that are deterministic, reviewable, and easy to run anywhere.
That is the slice of the QQL ecosystem qql-go is trying to own.
qql-go is just the retrieval operations piece, but it is a piece most vector search stacks are missing.
If you are working on the ingestion side of retrieval quality, RAG Chunking Visualizer in Rust (WebAssembly) is the upstream companion. If you care about agent execution boundaries, Governed Code Mode is the adjacent runtime story. And if your retrieval layer is becoming a maintained knowledge system, Schema-First Extraction for LLM Wikis is the next layer up.
References#
Footnotes#
-
Kameshwara Pavan Kumar Mantha. "QQL - Qdrant Query Language." GitHub. https://github.com/pavanjava/qql(opens in a new tab) ↩ ↩2
-
Srimon Danguria. "qql-go - A Single-Binary Operational CLI for Qdrant." GitHub. https://github.com/srimon12/qql-go(opens in a new tab) ↩
-
Evidently AI. "A complete guide to RAG evaluation: metrics, testing and best practices." https://www.evidentlyai.com/llm-guide/rag-evaluation(opens in a new tab) ↩
-
Braintrust. "RAG evaluation metrics: How to evaluate your RAG pipeline with Braintrust." https://www.braintrust.dev/articles/rag-evaluation-metrics(opens in a new tab) ↩
-
Srimon Danguria. "qql-go examples." GitHub. https://github.com/srimon12/qql-go/tree/main/examples(opens in a new tab) ↩ ↩2 ↩3
-
Qdrant. "Hybrid Queries." https://qdrant.tech/documentation/search/hybrid-queries/(opens in a new tab) ↩ ↩2
-
Qdrant. "Hybrid Search and the Universal Query API." https://qdrant.tech/course/essentials/day-3/hybrid-search/(opens in a new tab) ↩ ↩2
-
xpander.ai. "MCP vs CLI for AI Agents." https://xpander.ai/resources/mcp-vs-cli-for-ai-agents(opens in a new tab) ↩
-
Endor Labs. "Introducing Agent Governance: Using Hooks to Bring Visibility to AI Coding Agents." https://www.endorlabs.com/learn/introducing-agent-governance-using-hooks-to-bring-visibility-to-ai-coding-agents(opens in a new tab) ↩